
Label Embedding for Chinese Grapheme-to-Phoneme Conversion
Choi, Eunbi, et al. “Label Embedding for Chinese Grapheme-to-Phoneme Conversion}}.” Proc. Interspeech 2021 (2021): 4094-4098.
들어가며
중국어 G2P는 polyphone disambiguation을 해결하는 것이 핵심이라고 할 수 있다. 대부분의 문자들은 monophone이지만, 2개 혹은 3개의 발음을 가질 수 있는 polyphone이 존재하기 때문에 문맥에 따라서 polyphone의 발음을 알맞게 정해줄 수 있는 모델을 만들어야 한다.
본 논문은 label embedding을 적용해서 위의 문제를 해결하고자 한다. character embedding과 알맞은phoneme(pinyin)의 embedding이 서로 가까워지도록 triplet loss로 학습해서 character와 phoneme의 embedding을 같은 latent space 상에 매핑하는 연구다. 모델은 단순하게 BiLSTM을 사용했는데 성능은 one-hot label을 사용하는 경우보다 좋게 나왔고 BERT를 능가한다.
핵심 요약
- polyphone의 발음을 결정하기 위해서는 문맥을 이해하는 것이 필수이기 때문에 인코더에 BiLSTM 구조를 사용한다.
- phoneme label을 one-hot vector가 아닌 dense embedding으로 사용하여 task를 classification이 아닌 vector matching task로 전환하였다.
- polyphone의 발음 후보는 보통 2개 혹은 3개이므로 triplet loss를 계산할 때 사용하는 negative sample을 데이터셋 내의 모든 phoneme을 사용하는 것이 아니라 k개의 sample만 사용한다.
모델 구조
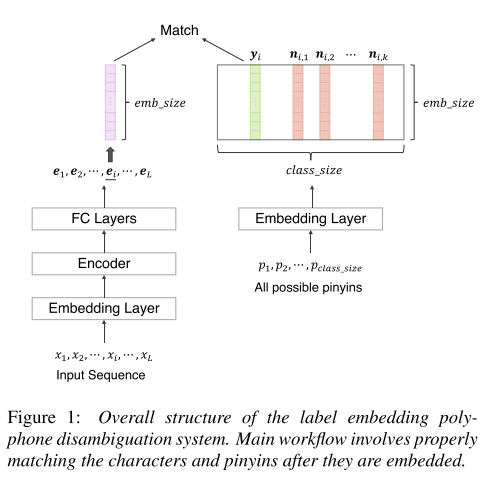
모델은 두 개의 임베딩 파트로 나뉜다. 그림 1의 왼쪽 파트는 입력으로 들어온 중국어 문장을 단어 단위로 쪼갠 뒤에 임베딩하는 과정이다. 먼저 단어가 임베딩 층을 통과한 뒤에 BiLSTM 인코더를 통과하면서 문맥의 정보를 담은 의미 있는 임베딩 벡터로 변환된다. 그리고 이를 FC 층을 통과시켜 최종 character representation을 만들어낸다. 오른쪽 파트에서는 후보가 되는 모든 pinyin들을 임베딩하는 과정을 거친다. 이때, 각 파트의 임베딩 사이즈는 동일하다.
학습 시에는 triplet loss를 사용해서 character embedding이 정답인 pinyin embedding과 가까워지고, 그 외의 negative sampling으로 뽑아낸 k개의 candidate pinyin embedding과는 멀어지도록 학습시킨다. 유사도는 cosine similarity를 이용하였다.
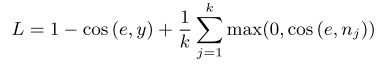
추론 시에는 주어진 character가 monophone인 경우에는 one-to-one mapping으로 pinyin을 뽑아내고, polyphone인 경우에는 가질 수 있는 후보 pinyin들의 embedding을 가져와서 character embedding과 가장 가까운 pinyin을 선택하여 G2P를 수행한다.
실험 결과
데이터셋으로 Data Baker Ltd Dataset과 직접 labeling한 Dataset을 사용했다.
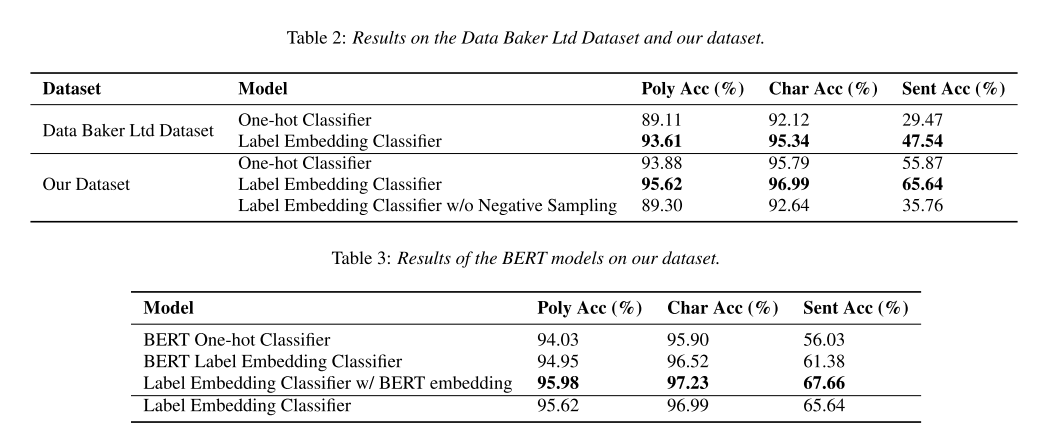
베이스라인은 제안하는 모델과 똑같은 BiLSTM을 사용하는 모델을 one-hot classifier로 사용한 경우다. 우선 표 2와 같이 베이스라인과 label embedding을 사용한 모델의 성능을 비교했을 때 두 데이터셋에서 모두 label embedding을 사용한 모델이 더 나은 성능을 보인다. 그리고 negative sampling을 제거하면 성능이 하락하는 것으로 보아 negative sampling이 오로지 후보 pinyin들에만 집중하는 효과를 주어서 polyphone disambiguation task에 더 적합하다는 것을 보여준다.
표 3에서는 BERT를 적용해보면서 비교를 해보았다. BERT로 one-hot vector를 뽑아내서 classifier로 사용한 모델, BERT로 label embedding을 뽑아낸 모델, 그리고 BERT로 초기의 character embedding만 추출하고 이후의 인코더로는 BiLSTM을 유지한 모델을 사용했다. BERT로 label embedding을 했을 경우 BiLSTM보다 낮은 성능이 나왔는데 그 이유는 BERT는 문자의 의미에 집중하는데 같은 의미를 지녀도 다른 pinyin을 가지는 문자들이 있어 이런 부분에 취약하기 때문일 것이다. 대신에 BiLSTM은 유지하고 BERT를 문맥 정보를 뽑기 위한 보조 임베딩으로 사용했을 때 성능이 더 향상되었다.
의견
- polyphone의 candidate pinyin만 negative sample로 사용하지 않고, 다른 pinyin도 일부 사용하여 임베딩을 학습하면 정말로 의미있는 임베딩 공간을 만들어낼 수 있을 것 같은데 이 경우에도 성능이 높게 유지될지 궁금하다.
- 성능 지표를 봤을 때 sentence accuracy는 다른 수치에 비해 현저히 낮은 결과를 보여준다. 즉, 문장 내에 모든 polyphone을 알맞은 pinyin으로 변환한 경우가 그만큼 적다는 의미인데 실제 TTS 사용자들이 느끼기에는 문장 내에 발음이 하나라도 틀리면 모델에 대한 신뢰가 크게 하락하게 된다. 그러므로 sentence accuracy를 많이 떨어뜨린 pinyin이 무엇인지 찾아내서 모델이 틀리게 된 원인을 알아내고 개선하는 과정이 필요해 보인다.




Leave a comment